
Aula de Rogério Júnior
Imagine o seguinte problema:
"Com a crise econômica internacional, as fusões entre bancos têm sido cada vez mais comuns; por isso, muitas vezes é difícil decidir se dois códigos bancários na realidade se referem ao mesmo banco (devido aos dois bancos terem se fundido, diretamente ou não). Assim, escreva um programa que, dada uma série de fusões entre bancos, responde a várias consultas perguntando se dois códigos bancários se referem ao mesmo banco."
O excerto acima é um trecho do problema Fusões, da segunda fase da P1 da OBI 2010. Se você não conhece o problema, clique aqui para ler seu enunciado completo. Hoje vamos tratar de problemas que envolvem união de conjuntos, onde unimos e checamos de maneira dinâmica. O que é isso? O que faz o Fusões ser um problema de Union-Find é o fato de, na entrada, o problema juntar bancos e consultar se estão no mesmo conjunto, tudo ao mesmo tempo, ou seja, de maneira dinâmica. Se primeiro, na entrada, houvesse m linhas informando todas as fusões de bancos e, depois disso, outras q linhas com as consultas, poderíamos fazer o problema olhando os bancos como vértices de um grafo e chamando uma DFS para marcar as componentes conexas em que eles estão, imprimindo 'S' se dois bancos estiverem na mesma e 'N' caso não estejam, com um programa semelhante ao desenvolvido na aula de Flood Fill. A única mudança seria essa checagem das componentes dos vértices consultados ao invés da impressão do número de componentes. Isso seria possível porque só precisaríamos chamar a DFS uma única vez, depois que todas as fusões fosse informadas. Entretanto, como o problema é dinâmico, teríamos que chamá-la várias vezes, a cada nova consulta, o que demoraria muito pois uma DFS tem complexidade O(n). Por isso, precisamos de uma técnica que tenha operações mais rápidas.
Um jeito muito eficiente de trabalharmos com união de conjuntos disjuntos (sem elementos pertencentes aos dois ao mesmo tempo, que é o que ocorre na maioria dos casos) é o algoritmo Union-Find. A ideia é muito simples: vamos juntar elementos como "membros de uma mesma família" e escolher um "patriarca" para cada família. Cada elemento terá seu elemento "pai", e aquele que não tem (que é pai de si mesmo), é o patriarca da família. Olhar se dois elementos estão na mesma família é muito simples, basta verificar se eles têm o mesmo patriarca! Suponha que o pai de cada elemento (identificado por um número de 1 a n) está salvo no vetor int pai[MAXN], onde pai[i] guarda o número do elemento que é o pai do elemento i. Desse modo, para encontrar o patriarca de i, basta olharmos seus ancestrais um a um até encontrarmos um patriarca (alguém que é pai de si mesmo). Para isso, vamos implementar a função recursiva int find(int x), que recebe um elemento x como parâmetro e retorna o número do patriarca da família de x. Se x for o patriarca, retornamos o seu valor ("if(pai[x]==x) return x;"). Se ele não for, fazemos o mesmo teste para o seu pai, retornando o seu patriarca com o comando recursivo "return find(pai[x]);". Observe na figura abaixo os 5 elemento representados por pontos. Aqui, de cada elemento sai uma seta que aponta para seu pai, que pode inclusive ser ele mesmo.
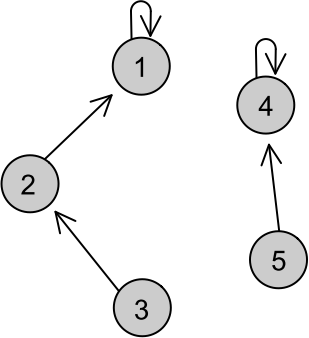
Note que, na figura, há 5 elementos identificados por números de 1 a 5. Eles estão divididos em duas famílias, cujos patriarcas são 1 e 4. Vamos simular a chamada de find(3). Assim que chamada, a função vai olhar se "pai[3]==3". Porém, o pai de 3 é 2, então ela vai continuar e retornar o find(pai[3]), que é o find(2). Novamente, ela vai olhar se "pai[2]==2", mas ele não é. A função então continuará e retornará o find(pai[2]), que é find(1). Logo no começo, a função verá que o pai de 1 é 1, logo ele é o patriarca e ela retornará seu valor: 1. Assim, find(2) também retornará 1 e find(3) também.
E para juntar dois elementos? Toda vez que dizemos que dois elementos quaisquer estão na mesma família, devemos fazer a união de todos os elementos das duas famílias em um conjunto só, ou seja: devemos associar o mesmo patriarca a todos eles. Para isso, basta que façamos o patriarca de uma família ser o pai do patriarca da outra, assim todos os descendentes do ex-patriarca agora serão descendentes do novo patriarca de todo o conjunto! Mesmo no caso em que os dois elementos já estavam no mesmo conjunto, seus patriarcas serão o mesmo elemento e ele se tornará pai de si mesmo, continuando a ser o patriarca. Vale lembra que para encontrarmos o patriarca do elemento x, basta chamarmos a função find(x). Para a implementação da união de dois conjuntos, não podemos criar a função de nome union, pois esta é uma palavra restrita do C++. Ao invés disso, vamos criar a função void join(int x, int y), que recebe os números de dois elementos e faz o patriarca de um deles se tornar filho do patriarca do outro, através do comando "pai[find(x)]=find(y);". Observe, na figura abaixo, como ficará a distribuição das famílias mostradas no exemplo anterior após o comando "join(3, 5);":
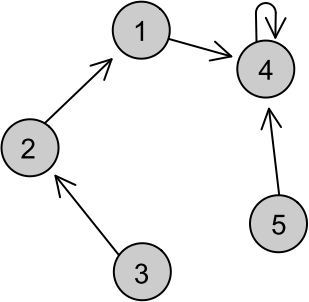
Vamos simular o que a função fez: ela recebe dois valores como parâmetros, que são x e y. No caso, x=3 e y=5. Ela irá transformar o patriarca de x em um filho do patriarca de y. Já vimos na simulação anterior que o patriarca de 3 (find(3)) é 1, e é fácil notar na figura que o find(5) é 4. Assim a função fará com que o pai de 1 se torne 5, ou seja o comando "pai[find(3)]=find(5);" fará "pai[1]=4". Ou seja, 1 deixará de ser pai de si mesmo e passará a ser um filho de 4, como mostra a seta da figura.
Seguem as implementações das duas funções em C++:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| #define MAXN 100100 | |
| int pai[MAXN]; // crio o vetor que armazenará os pais | |
| // função find: retorna o patriarca de um elemento x | |
| int find(int x){ | |
| // se ele for pai de si mesmo, ele é o patriarca | |
| if(pai[x]==x) return x; | |
| // se não, devo olhar o patriarca de seu pai | |
| return find(pai[x]); | |
| } | |
| // função join: faz a união dos conjuntos dos elementos x e y | |
| void join(int x, int y){ | |
| // basta fazer o patriarca de um se tornar pai do patriarca do outro | |
| pai[find(x)]=find(y); | |
| } |
Vale ressaltar ainda que, na main, devemos preparar o vetor pai. Note que antes de realizarmos qualquer união, todos elementos estão sozinhos em seu próprio conjunto, ou seja: todos são patriarcas de si mesmos. Por isso, antes de começarmos a usar o algoritmo, devemos percorrer o vetor pai fazendo com que cada elemento seja pai de si mesmo. O algoritmo mostrado acima encontra o patriarca de um elemento e junta dois conjuntos em complexidade O(log n), onde n é o número de elementos no universo do problema.
Assim, vamos resolver o problema Fusões. Para cada uma das k operações, vamos ler um caractere op, que indicará a operação a ser realizada (fusão ou consulta) e dois inteiros banco1 e banco2, que serão os identificadores dos bancos com os quais realizaremos a operação. Se op for o caractere 'F', devemos fundir, juntar os bancos banco1 e banco2 em um novo conjunto que conterá eles e todos os que já estavam a eles fundidos, ou seja, eles e suas famílias. Logo devemos realizar o comando "join(banco1, banco2)". Se op não for 'F', então ele será 'C' e devemos consultar se banco1 e banco2 estão no mesmo conjunto, ou seja se eles têm o mesmo patriarca. Para isso, vamos verificar se find(banco1)==find(banco2). Se eles forem iguais, imprimimos 'S', caso contrário, imprimimos 'N'. Segue o código comentado:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| #include <cstdio> | |
| #define MAXN 100100 | |
| int n, k; | |
| int pai[MAXN], peso[MAXN]; | |
| // funções do Union-Find | |
| int find(int x){ | |
| if(pai[x]==x) return x; | |
| return find(pai[x]); | |
| } | |
| void join(int x, int y){ | |
| pai[find(x)]=find(y); | |
| } | |
| int main(){ | |
| // leio os valores de n e k | |
| scanf("%d %d", &n, &k); | |
| // inicializo todos os bancos como pais de si mesmos | |
| for(int i=1; i<=n; i++) pai[i]=i; | |
| char op; | |
| int banco1, banco2; | |
| // para cada operação a ser realizada | |
| for(int i=1; i<=k; i++){ | |
| // leio o tipo de operação e os bancos envolvidos | |
| scanf(" %c %d %d", &op, &banco1, &banco2); | |
| // se a operação for a de fusão | |
| if(op=='F') join(banco1, banco2); // realizo a união dos conjuntos | |
| // se não for, é uma consulta | |
| else{ | |
| // se os bancos estiverem no mesmo conjunto | |
| if(find(banco1)==find(banco2)) printf("S\n"); // imprimo 'S' | |
| // se não, imprimo 'N' | |
| else printf("N\n"); | |
| } | |
| } | |
| return 0; | |
| } |
Entretanto, esse código ainda leva TLE nos corretores, por isso vamos para o próximo tópico da aula:
Otimizações do Union-Find
Union-Find é um algoritmo mágico quando bem implementado. As funções mostradas em O(log n) terão complexidade de praticamente O(1) ao final de todas as otimizações (Terá complexidade inversa à da função de Ackermann). A primeira e mais simples otimização do algoritmo está na busca do patriarca de um elemento, ou seja, na função find. Observe que se fizermos a função find de maneira rápida, a função join fica automaticamente rápida também, pois tudo que ela realiza, que gasta tempo, são as duas chamadas de find. Note que o que gasta tempo na função é chamarmos a recursividade por todos os ancestrais de um determinado elemento. Porém, podemos usar um princípio de Programação Dinâmica: evitar o recálculo! Uma vez que calcularmos o patriarca de um elemento x (find(x)), podemos salvá-lo diretamente como seu pai ("pai[x]=find(x);"). Assim, das próximas vezes que formos calcular o valor de find(x), a função retornará seu patriarca muito rápido, pois ele já estará salvo em pai[x], o que evita percorrermos todos os ancestrais que vinhem entre x e o patriarca. Para fazer essa otimização basta que, na hora de retornarmo o valor de find(x), o salvemos em pai[x], como fazíamos na PD. Segue a implementação da função find otimizada:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| // função find otimizada | |
| int find(int x){ | |
| // se x for o patriarca, retorne x | |
| if(pai[x]==x) return x; | |
| // se não, retorne o valor do patriarca de seu pai | |
| return pai[x]=find(pai[x]); // mas lembre-se de salvá-lo em pai[x] | |
| } |
Este pequeno detalhe, sozinho, já é muito poderoso e deixa o algoritmo muito mais rápido. Só com essa pequena diferença, o código de Fusões já é aceito, e é muito fácil entender porque a otimização funciona. Vejamos agora como otimizar a função join. Repare novamente nas ilustrações acima de um pequeno universo de elementos separados em dois conjuntos que desejo unir. Você consegue notar que existia um jeito melhor de realizar a união entre os conjuntos? Note que fizemos 4 ser o pai de 1. Desse modo, se chamássemos o find(3), ele teria que percorrer outros 3 ancestrais (2, 1 e 4) até encontrar o patriarca. Mas, e se tivéssemos feito o 1 ser o pai do 4? Os conjuntos continuariam unidos, pois todos os elementos teriam o mesmo patriarca, mas agora os elementos mais distantes do 1 (o novo patriarca) seriam o 3 e o 5, cada um a dois ancestrais de distância dele, ou seja, teriam que chamar a recursão apenas duas vezes, o que é mais rápido que o modo anterior. Parece pouco, mas em universos muito grandes de elementos, essa otimização pode ser a diferença entre o accepted e o TLE.
Para cada patriarca, devemos ter salvo a distância do descendente que está mais longe dele, que vamos salvar no vetor peso. Assim, peso[i] irá guardar o descendente do elemento i que está mais longe dele. Agora, toda vez que formos unir dois patriarcas x e y vamos olhar qual dos dois tem o maior peso. Se o descendente mais distante de x está mais perto dele do que o descendente mais distante de y está do seu patriarca devemos fazer y ser o pai de x, pois a distancia dele até seu descendente mais longe não será alterada, note: a distância h do descendente mais longe de x até seu patriarca será agora h+1, pois seu novo patriarca será y, e a distância entre eles será a distância que ele tinha até x (h), somada de 1, que representará a filiação de x a y. A maior distância de y até um de seus descendentes já era maior que h, logo não será menor que h+1. Se os dois (x e y) tiverem o mesmo peso (as distâncias até os descendentes mais longe são iguais), fazemos qualquer um ser o novo patriarca (digamos que será y) e guardamos que seu peso aumentará em uma unidade, pois agora será a distância de y até x, que é 1, somada com a maior distância de x a um de seus descendentes. Nessa otimização, para que não aumentemos os pesos de maneira errada, devemos verificar, na função join, os conjuntos a serem unidos não são iguais, pois, se forem, nada deverá ser feito e a função deve retornar, visto que os conjuntos já estão unidos. Observe como ficaria a figura acima se chamássemos a função join(3, 5) otimizada:
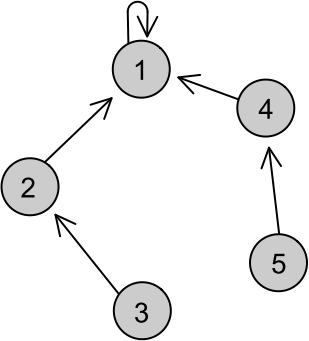
Note que a distribuição é bem mais simétrica, o que evita descendentes muito longes do patriarca e gera a otimização acima. Segue a implementação da função join otimizada:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| // função join otimizada | |
| void join(int x, int y){ // ela recebe os elementos a serem unidos | |
| // como só vamos unis os patriaarcas só precisamos trabalhar com eles | |
| // e fazemos caa um dos elementos receber o valor de sue patriarca | |
| x=find(x); | |
| y=find(y); | |
| // agora x e y são os patriarcas dos conjuntos que desejamos unir | |
| // se eles forem o mesmo patriarca | |
| if(x==y) return; // então os conjuntos já estão unidos e retornamos | |
| // se um dos dois patriarcas tiver peso menor, faço ele ser filho do outro | |
| if(peso[x]<peso[y]) pai[x]=y; | |
| if(peso[x]>peso[y]) pai[y]=x; | |
| // se os dois tiverem o mesmo peso | |
| if(peso[x]==peso[y]){ | |
| // escolho um para ser o novo patriarca | |
| pai[x]=y; | |
| // e guardo que seu peso aumentará um uma unidade | |
| peso[y]++; | |
| } | |
| } |
Essa implementação do Union-Find com suas duas funções bem otimizadas é mágica! Você pode considerar que ambas têm complexidade apenas de O(1) e fazer tranquila e eficientemente todos os problemas que precisar. Para encerrar a aula, segue a solução do problema fusões usando o Union-Find otimizado, que responde com tempo de sobra o problema. Os limites podiam ir até  que o programa ainda passaria no tempo de maneira muito tranquila. Observe que você pode declarar o vetor peso zerado, pois o importante são as comparações de quem tem o maior peso.
que o programa ainda passaria no tempo de maneira muito tranquila. Observe que você pode declarar o vetor peso zerado, pois o importante são as comparações de quem tem o maior peso.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| #include <cstdio> | |
| #define MAXN 100100 | |
| // declaro as variáveis que vou precisar | |
| int n, k, pai[MAXN], peso[MAXN]; | |
| // funções do Union-Find otimizadas | |
| int find(int x){ | |
| if(pai[x]==x) return x; | |
| return pai[x]=find(pai[x]); | |
| } | |
| void join(int x, int y){ | |
| x=find(x); | |
| y=find(y); | |
| if(x==y) return; | |
| if(peso[x]<peso[y]) pai[x]=y; | |
| if(peso[x]>peso[y]) pai[y]=x; | |
| if(peso[x]==peso[y]){ | |
| pai[x]=y; | |
| peso[y]++; | |
| } | |
| } | |
| // os comandos da main seguem os mesmo do código anterior, não otimizado | |
| int main(){ | |
| scanf("%d %d", &n, &k); | |
| for(int i=1; i<=n; i++) pai[i]=i; | |
| char op; | |
| int banco1, banco2; | |
| for(int i=1; i<=k; i++){ | |
| scanf(" %c %d %d", &op, &banco1, &banco2); | |
| if(op=='F') join(banco1, banco2); | |
| else{ | |
| if(find(banco1)==find(banco2)) printf("S\n"); | |
| else printf("N\n"); | |
| } | |
| } | |
| return 0; | |
| } |
Tamanho dos conjuntos
Outra coisa muito importante do Union-Find é que, fazendo uma pequena mudança na função join, podemos saber quantos elementos tem um determinado conjunto em O(1). Assim como criamos o vetor peso para guardarmos a distância do descendente mais longe de cada patriarca, podemos criar o vetor qtd, de modo que qtd[i] guardará a quantidade de descendentes que o patriarca i tem. Desse modo, para sabermos quantos elementos tem o conjunto do elemento x, basta olharmos quantos descendentes o patriarca de x tem, (qtd[find(x)]). No começo, todos são pais de si mesmos, logo o vetor deve começar com todos os seus valores iguais a 1. Agora, toda vez que fizermos um patriarca x se tornar filho de outro patriarca y, devemos atualizar a quantidade de descendentes de y, pois agora todos os descendentes de x são descendentes dele também, ou seja, devemos adicionar a quantidade de descendentes de x à quantidade de descendentes de y ("qtd[y]+=qtd[x];"). Segue o código da função join que também guarda a quantidade de descendentes de um patriarca no vetor qtd:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| // função join otimizada que atualiza o tamanho dos conjuntos | |
| void join(int x, int y){ // ela recebe os elementos a serem unidos | |
| // como só vamos unis os patriaarcas só precisamos trabalhar com eles | |
| // e fazemos caa um dos elementos receber o valor de sue patriarca | |
| x=find(x); | |
| y=find(y); | |
| // agora x e y são os patriarcas dos conjuntos que desejamos unir | |
| // se eles forem o mesmo patriarca | |
| if(x==y) return; // então os conjuntos já estão unidos e retornamos | |
| // se o patriarca x tiver peso menor que o patriarca y | |
| if(peso[x]<peso[y]){ | |
| pai[x]=y; // faço x ser filho do y | |
| qtd[y]+=qtd[x]; // e atualizo o número de descendentes de y | |
| } | |
| // se o patriarca y tiver peso menor que o patriarca x | |
| if(peso[x]>peso[y]){ | |
| pai[y]=x; // faço y ser filho de x | |
| qtd[x]+=qtd[y]; // e a tualizo o número de descendentes de x | |
| } | |
| // se os dois tiverem o mesmo peso | |
| if(peso[x]==peso[y]){ | |
| // escolho um para ser o novo patriarca | |
| pai[x]=y; | |
| // e guardo que seu peso aumentará um uma unidade | |
| peso[y]++; | |
| // e atualizo o seu número de descendentes | |
| qtd[y]+=qtd[x]; | |
| } | |
| } |
Agora que você já sabe tudo isso, tente resolver os problemas abaixo. Se você não conseguir resolver algum deles ou surgir alguma dúvida na parte teórica, volte para a página inicial do curso e preencha o formulário para nos enviar sua dúvida!
Problema 1 - Gincana (tente fazer com Union-Find. Se não conseguir, clique aqui para ver a solução do Noic com esse algoritmo)
Problema 2 - War
Problema 3 - Montesco vs Capuleto
Problema 4 - Ubiquitous Religions
Problema 5 - Virtual Friends
As aulas do Curso Noic de Informática são propriedade do Noic e qualquer reprodução sem autorização prévia é terminantemente proibida. Se você tem interesse em reproduzir algum material do Curso Noic de Informática para poder ministrar aulas, você pode nos contatar por esta seção de contato para que possamos fornecer materiais específicos para reprodução.