
Comentário por Rogério Júnior
Para ver o caderno de tarefas da segunda fase da Programação Nível 2 da OBI 2015, clique aqui.
Macacos me mordam!
Conhecimento prévio necessário
- Geometria Computacional (Produto vetorial)
O enunciado é uma adaptação simplificada do problema de encontrar o Fecho Convexo. A primeira coisa que devemos fazer é tratar os topos das árvores como pontos no plano cartesiano e salvá-los em um vetor de pontos de nome tree. Vamos representar um ponto como um par de inteiros e chamá-lo de dot. Essa estrutura terá dois membros: X e Y, que representam as coordenadas do ponto. Depois que salvarmos todos os pontos no vetor tree, vamos ordená-los pela coordenada X.
Observemos agora três árvores quaisquer (digamos A, B e C, nesta ordem) do percurso feito pelo macaco. Observe que se as três estão no percurso, então é impossível pular direto de A para C, ou seja, de A, não é possível ver C, pois B está no meio. Isso significa, explicitamente, que o ângulo (com direção cartesiana, ou seja, anti-horária)  é convexo. Veja, lembrando que A, B e C estão ordenados por coordenada X:
é convexo. Veja, lembrando que A, B e C estão ordenados por coordenada X:
côncavo: o macaco consegue pular de A para C
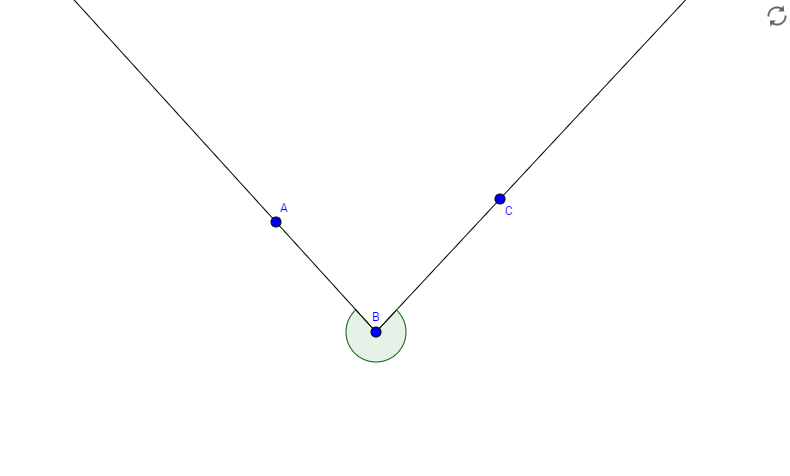
convexo: o macaco não consegue pular de A para C

Deste modo, dentre todas as árvores selecionadas, não pode haver três que formam um ângulo côncavo. Agora observe a seguinte propriedade: sejam A, B, C e D pontos ordenados pelo eixo X. Se é côncavo e  também é côncavo, então
também é côncavo, então  é côncavo.
é côncavo.

Observe, na figura acima, o polígono ABCD e seus respectivos ângulos internos  ,
,  ,
,  e
e  . Sabemos que:
. Sabemos que:

Mas 
Com isso, vamos olhar um a um os pontos ordenadamente. Guardaremos uma pilha que, ao final do algoritmo, será nosso caminho. Note que, pela definição que encontramos, estamos buscando a parte superior do fecho convexo dos pontos. Adicionaremos um a um todos os pontos à pilha. Entretanto, antes de adicionarmos um ponto, temos que garantir que ele não forma um ângulo côncavo com seus dois anteriores, removendo o último ponto da pilha enquanto o ângulo formado for côncavo. Quando enfim o novo ponto formar um ângulo convexo, o adicionamos ao topo da pilha.
Note que a propriedade mostrada acima garante que todos os pontos que foram tirados para que um determinado ponto C fosse inserido realmente não participam do fecho convexo, mesmo que posteriormente C seja retirado para inserirmos um ponto D.
O único problema que ainda falta resolvermos é como descobrir se o ângulo é côncavo ou convexo. Felizmente, produto vetorial transforma isso em uma tarefa muito fácil. Olhar o ângulo é o olhar o ângulo formado pelos vetores  e
e  , e sabemos que se este ângulo for côncavo, o produto
, e sabemos que se este ângulo for côncavo, o produto  será negativo. Assim, para implementarmos a função chega que recebe três pontos A, B e C como parâmetros e retorna true se o macaco consegue pular de A para C sem parar em B, basta implementarmos o produto citado acima e verificarmos se ele é negativo.
será negativo. Assim, para implementarmos a função chega que recebe três pontos A, B e C como parâmetros e retorna true se o macaco consegue pular de A para C sem parar em B, basta implementarmos o produto citado acima e verificarmos se ele é negativo.
No fim do algoritmo, teremos todas as árvores pelas quais o macaco passa. Para pular entre  árvores, ele dá
árvores, ele dá  pulos, logo basta imprimirmos o número de árvores na pilha subtraído de uma unidade. Segue o código para melhor entendimento.
pulos, logo basta imprimirmos o número de árvores na pilha subtraído de uma unidade. Segue o código para melhor entendimento.
A complexidade é O(n og n) devido à ordenação dos pontos. Além disso, note que é muito importante o uso de long long por multiplicarmos números que podem ir até  .
.
Chocolate em barra
Conhecimento prévio necessário:
Só há duas possibilidades de divisão do chocolate: dividi-lo verticalmente ou horizontalmente. Seja n o tamanho do lado do tabuleiro, x1 e y1 as coordenadas da primeira figurinha e x2 e y2 as coordenadas da segunda. Para que o tabuleiro seja divisível na horizontal, uma figurinha deve estar na metade superior e outra na inferior, ou seja: o menos dos y deve ser menor ou igual a n/2 e o maior deles maior que n/2. Em C, a condição ficaria "if(min(y1,y2)<=n/2 && max(y1,y2)>n/2)". De maneira análoga, para dividirmos verticalmente o tabuleiro, uma figurinha deve estar na esquerda e outra na direita, ou seja "if(min(x1,x2)<=n/2 && max(x1,x2)>n/2)". Se qualquer uma das duas condições citadas for atendida, podemos dividir o tabuleiro e devemos imprimir uma única linha com o caractere 'S'. Caso contrário, uma com o caractere 'N'. Segue o código para melhor entendimento:
Mina
Conhecimento prévio necessário:
O problema é uma aplicação direta do Algoritmo de Dijkstra. No algoritmo, a matriz que representa a mina será vista como um grafo em que cada casa é um vértice. Cada vértice estará ligado a todos os seus vizinho na matriz e o peso da aresta desta ligação será 1 ou 0, dependendo do valor de explorar este vizinho. A única diferença do algoritmo aqui mostrado para o da aula do Curso será que este vai rodar em O(E log V) (E é o número de arestas e V o de vértices) porque usaremos uma heap (priority_queue) para guardarmos os vértices mais próximos da origem durante a execução do Dijkstra. Note que, para guardarmos os vértices usaremos um par de inteiros (que chamaremos de ii). No caso, o par (i, j) faz referência à casa da linha i, coluna j. Veja o código:
Cálculo
Conhecimento prévio necessário
- Vetores (Aula 3 do Curso Noic)
Observe que a operação descrita no enunciado é extremamente parecida com uma soma normal de dois números binários, com apenas duas diferenças:
- Os números são somados da esquerda para a direita (a primeira casa sempre representa
 )
) - Zeros à direita não têm valor (definição do enunciado)
Vamos explicar melhor estes dois detalhes. O primeiro significa que vamos somar, casa a casa, os números da esquerda para a direita, ao invés do padrão contrário que geralmente usamos em somas e subtrações. Isto ocorre porque agora a primeira casa tem um valor fixo, ao contrário de uma operação normal de adição onde a casa com valor fixo é a última (casa das unidades). O segundo detalhe vem de o enunciado falar para sempre usarmos o menor número de dígitos possível, logo, não há para que imprimirmos zeros à direita do número, pois 1010000, por exemplo, é o mesmo que 101. Agora, que sabemos disso, basta somarmos os números. Vamos usar três vetores de inteiros: o num1, num2 e resp. Os dois primeiros irão guardar os números que devemos somar, enquanto que resp guardará o resultado final. Usaremos um for para percorrermos e somarmos os dois números, guardando esta soma em resp. Feito isso, resp[i] será igual a num1[i]+num2[i] para todo i. Agora, vamos percorrer resp de trás para frente procurando por casas sobrecarregadas (posições que guardam valores maiores que 1). Se o valor de uma casa for maior que 1, devemos fazer como uma soma normal: subtrair 2 da casa (porque 2 é a base) e adicionar uma unidade à casa anterior. O enunciado garante que a primeira casa nunca estará sobrecarregada, pois o número é sempre menor que 1. Feito isso, basta descobrirmos onde está o último dígito da resposta que não é zero (podemos fazer isso com um for que percorre a resposta atualizando uma variável tam para a posição em que está toda vez que encontra um dígito não nulo) para só a imprimirmos até aí, evitando impressão de zeros à direita. Segue o código para melhor entendimento:
Fila
Conhecimento prévio necessário
- Implementação e busca rápida em BIT (Binary Indexed Tree)
- Implementação e busca rápida em Árvore de Segmentos
Este é com certeza um dos problemas mais difíceis que já caiu na P2 da OBI, por exigir um conhecimento bem alto de estruturas de dados, no caso, implementação e busca rápida em BIT e Árvore de Segmentos.
Primeiramente, vamos ler toda a entrada como um conjunto de operações dos tipos descritos no enunciado. Para isso, faremos com que a fila comece vazia e seu estado inicial será construído adicionando, um a um, todos os competidores em suas respectivas posições através da operação 0. Feito isso, haverá agora n+q operações (pois teremos que adicionar os n competidores iniciais). Guardaremos todas essas operações usando três vetores: t, p e x, que guardam os inteiros que descrevem uma operação, nesta ordem.
A principal dificuldade do problema é a dinamicidade da fila, visto que seu tamanho varia com o problema. Para driblarmos este problema, usaremos consulta offline, ou seja, iremos ler todas as operações para só então resolvermos o problema. Assim, imagine que a fila é estática e tem n+q posições. Nesta fila estática, a posição de cada competidor é sua posição final na fila do problema após todas as operações serem feitas, não a posição em que ele começa. Mas como descobrimos a posição final de cada competidor?
Para isso, usaremos um BIT. Ele terá n+q posições e representará o estado atual da fila. Seja pos(i) o número que está salvo na posição i do vetor que o BIT está representando. Neste caso, se pos(i) = 1, então o competidor que ocupa a posição i de nossa fila estática já está nela. Se pos(i) = 0, então tal competidor não está. A fim de descobrirmos a posição de cada competidor, iremos processar a entrada na ordem inversa. Note que o estado da fila após a última operação é ela cheia, logo, iremos percorrer o BIT fazendo cada uma de suas posições receber o número 1.
Agora, a ideia é percorrermos as operações fazendo com que, ao olharmos a operação i, o BIT represente o estado da fila logo após tal operação ter sido realizada. Como mostrado acimo, isso é verdade para a primeira iteração. Com a ajuda do BIT, é fácil descobrir as verdadeiras posições de cada elemento.
Suponha que estamos olhando a operação i. Se t[i]=0, então i é uma operação de inserção. Nesta operação, inserimos um competidor de altura h[i] na posição p[i]+1. Observando nossa fila estática, em que algumas posições ainda podem faltar, sabemos que o competidor que acaba de ser inserido é que é antecedido por exatamente p[i] competidores já inseridos. Como cada competidor que está na fila contribui com 1 para a soma da BIT, basta usarmos uma busca rápida na BIT para encontrarmos a última posição cuja soma de todos os termos até ela é exatamente p[i]. Seja p' tal posição. Sabemos então que p'+1 é a primeira posição cuja soma de todos os termos do BIT até ela (inclusive) é p[i]+1, logo p'+1 é a posição na fila estática (posição final) em que foi inserido o competidor na operação i. Sabemos disso, alteramos o valor de p[i] para p'+1. Além disso, para garantir que a BIT continuará representando a fila para operações que vieram antes de i (e que ainda serão processadas, pois lembre-se que as estamos lendo na ordem inversa), devemos tirar do BIT o elemento que a operação i insere, para que ele represente a fila exatamente após a operação que antecede i. Sabemos que este é o elemento da posição p[i] (pois a atualizamos), logo basta retirarmos uma unidade desta posição da BIT.
Se, por outro lado, o valor de t[i] for 1, então a operação i é uma operação de busca. Porém, precisamos saber qual a posição na fila estática do competidor que usaremos como referência para nossa busca. Para tal, de maneira análoga ao outro tipo de operação, basta vermos qual a última posição da BIT cuja soma até ela é p[i] e adicionarmos 1, atualizando o valor de p[i] para esta posição.
Agora, sabemos a posição final de cada elemento usado por cada operação da entrada, o que facilita toda a solução do nosso problema. Iremos representar nossa fila estática por uma árvore de segmentos de máximo. Note que o BIT agora está completamente zerado, pois após termos processado todas as operações de inserção no passo anterior, todos os elementos terão sido retirados. O BIT agora continuará representando nossa fila, juntamente com a árvore de segmentos, para sabermos que elementos já estão em suas posições.
Dito isso, basta agora realizarmos as operações na ordem em que elas aparecem. Suponha que estamos processando a operação i. Se ela for do tipo 0, é fácil: inserimos o número h[i] na posição p[i] da árvore de segmentos, e adicionamos 1 à posição p[i] do BIT, pois agora p[i] representa a posição a qual cada operação se refere na nossa fila estática. Além disso, usaremos o vetor h para guardarmos que o elemento da posição p[i] tem altura x[i] ("h[p[i]]=x[i];"). Por outro lado, se a operação for do tipo 1, precisamos encontrar o elemento mais à direita da fila que não está após p[i] mas é maior que o elemento da posição p[i] por mais que x[i]. Seja h' a altura que tal elemento deve superar. A altura do elemento da posição p[i] é h[p[i]], logo h'=h[p[i]]+x[i]. Sabendo disso, basta procurarmos de maneira rápida na árvore de segmentos por este elemento com altura maior que h'. Precisamos então encontrar a posição p' do elemento mais a direita da fila que não está depois de p[i] e supera h': basta usarmos uma busca binária na árvore! Note que as posições vazias de elementos não inseridos não irão interferir na busca pois guardam o valor 0. Encontrada p', precisamos imprimir a posição atual na fila do elemento que está nessa posição, ou seja, contar quantos elementos estão atrás dele, mais ele. Para isso, basta imprimirmos a soma do BIT até a posição p', pois cada elemento contribui com 1 na soma.
Este comentário não tem como objetivo ser uma aula sobre buscas binárias em árvore de segmento e BIT, visto que estes foram apresentados como conhecimentos prévios necessários para que você entenda a solução do problema. O link apresentado para SegTree é uma introdução a esta estrutura de dados, mas o site fornecido apresenta muito mais aprofundamento sobre ela se você continuar lendo seus artigos sobre o assunto. Deste modo, o que farei será uma breve explicação da implementação das operações com estas estruturas, embutidas no próprio código que segue abaixo, mas é altamente recomendável que você leia as páginas citadas se não conhece as estruturas ou as operações:
Se você ainda tiver alguma dúvida em algum dos problemas, vá para a página inicial do Curso Noic de Informática e preencha o formulário para nos enviar sua dúvida.