
Escrito por Miguel Cyrineu Vale
Essa página assume que você já está confortável com o conceito de Regressão Linear.
Tópicos Abordados
- Fundamentos e intuição
- Métricas de Avaliação
- Regressão Polinomial Multivariada
- Intuição Matemática
Fundamentos e Intuição
Após descobrir o poder da regressão linear, você começa a buscar problemas no mundo real para tentar resolver utilizando modelos lineares. No entanto, em uma dessas aventuras, você encontra um problema: nem tudo pode ser modelado por uma relação linear – isto é, algo que é ou diretamente ou inversamente proporcional a um grupo de parâmetros.
Para deixar isso mais claro, vamos imaginar a seguite situação: você quer fazer um modelo que diz o quão efetivo cada dose de um medicamento é, em diferentes pessoas. Para fazer isso, você coleta alguns dados de hospitais que testaram diferentes doses de um medicamento em pacientes, e anotaram o efeito. Aqui está o que você conseguiu de dados:
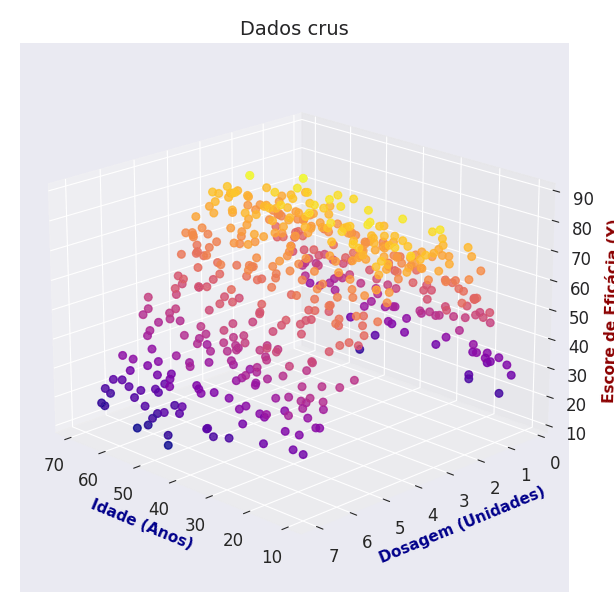
Como ficou evidente que a dosagem é o que mais afeta a eficácia, vamos isolá-la e ver o que temos:
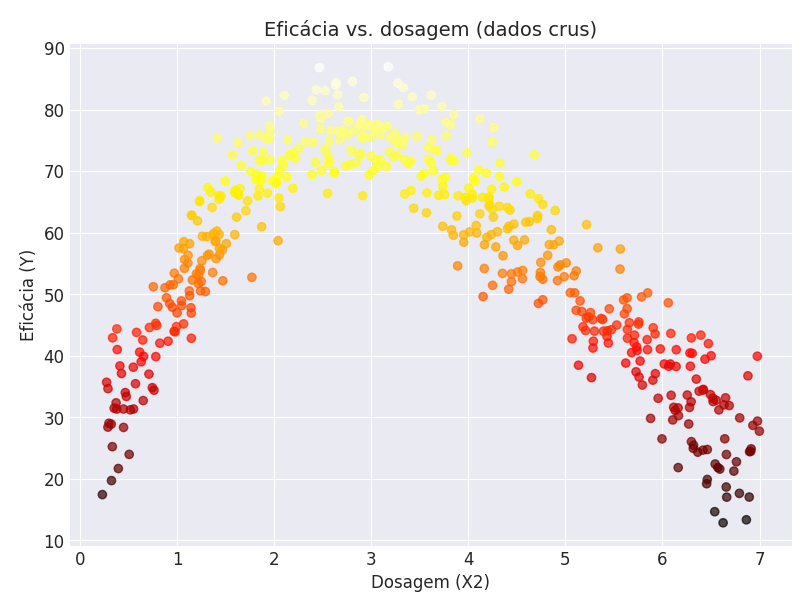
Aqui, temos uma tendência bastante clara e estável: doses muito baixas não funcionam tão bem, mas doses muito altas são igualmente ruins, provavelmente por conta de efeitos colaterais por conta das doses exageradas.
Com esses dados, você tenta usar a Regressão linear, mas obtém este resultado:
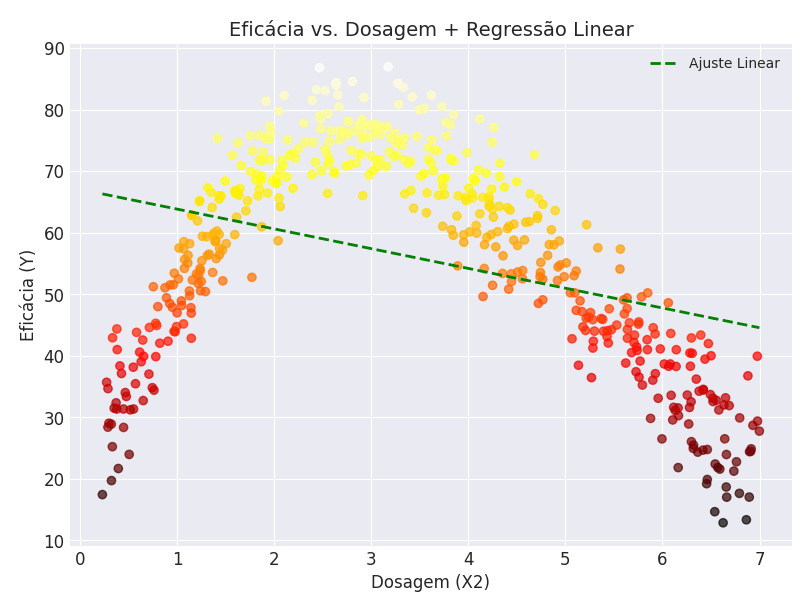
Onde  .
.
Evidentemente, esta é uma modelagem terrível dos dados coletados. Primeiramente, de acordo com ela, a melhor dose é 0 (nenhum remédio), mesmo que a eficácia nesse ponto seja efetivamente 0. Além disso, o ajuste e os dados não tem nenhuma semelhança – indicado pelo coeficiente de correlação baixíssimo (para este caso,  , ou seja, o modelo explica apenas 13% da relação).
, ou seja, o modelo explica apenas 13% da relação).
Mas, pensando sobre o funcionamento da regressão linear, algo fica claro: O problema não está em como você usou o algoritmo, está no algoritmo em si. Como o próprio nome diz, a regressão linear modela relações lineares entre features (neste caso, a dosagem) e o valor alvo (neste caso, a eficácia). Ou seja, ela funciona se um é *linearmente* proporcional ao outro (y aumenta quando x aumenta; ou y diminui quando x aumenta). Mas, nesse caso, a relação não é linear: a eficácia (y) pode tanto aumentar quanto diminuir de acordo com a dose (x): tanto doses pequenas quanto doses altas são ineficazes.
Como nosso problema é não linearmente separável, precisamos de um modelo não-linear – e é aí que a regressão polinomial entra. Assim como a regressão linear era modelada por uma função linear, a regressão polinomial é modelada por um polinômio. Assim, definimos ela:

Ao aplicar esse modelo e ajustar seus parâmetros aos nossos dados, conseguimos a seguinte curva:
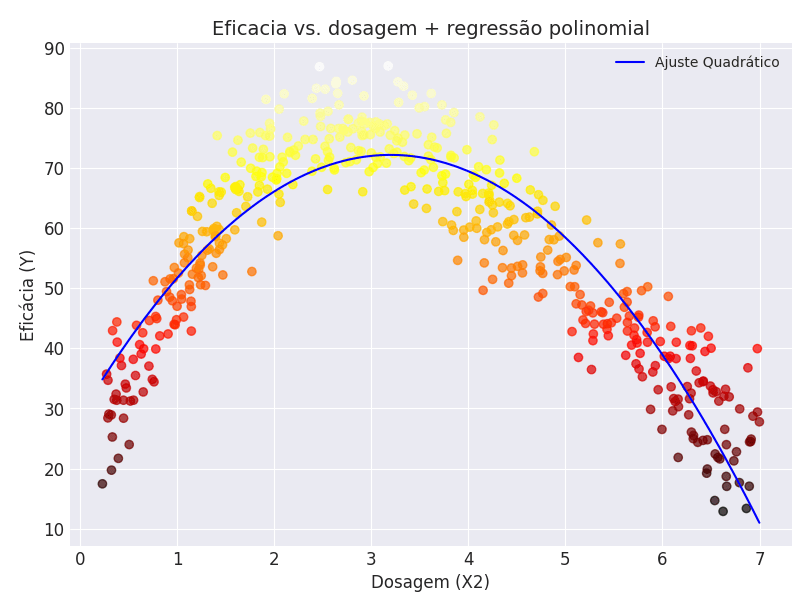
Onde  .
.
Claramente, esse polinômio modelou nosso caso de maneira muito melhor, gerando um coeficiente de determinação  (ou seja, o modelo explica
(ou seja, o modelo explica  da relação entre a dosagem e a eficácia).
da relação entre a dosagem e a eficácia).
E, de maneira idêntica às outras regressões, para fazermos uma predição, é só jogar o x na função:

Ou seja, a eficácia de uma dose “ ” num paciente deverá ser de aproximadamente
” num paciente deverá ser de aproximadamente  .
.
Métricas de avaliação
Para avaliar um modelo de regressão polinomial, temos duas técnicas comumente utilizadas: o coeficiente de determinação (ou  ), e as funções de erro (como já foi abordado na Regressão Linear).
), e as funções de erro (como já foi abordado na Regressão Linear).
As funções de erro são relativamente simples de se entender, e nos dão uma boa medida do quanto nosso modelo está “errando”. As duas mais comuns para problemas de regressão são a MAE (Mean Absolute Error; Média do Erro Absoluto) e a MSE (Mean Squared Error; Média do Erro ao Quadrado). Vamos começar pelo MAE.
MAE
Para um ponto qualquer, a definição de MAE é, como o próprio nome diz, o valor absoluto do erro:

Lembrando que o módulo aqui é para não fazer com que erros negativos cancelem erros positivos.
Entretanto, como queremos o erro absoluto médio, somamos o erro de todos os pontos e dividimos pela quantidade deles. Se tivermos  pontos, teremos:
pontos, teremos:

O MAE é bastante utilizado em modelos de IA em geral, pois é simples e interpretável, nos dando uma noção prática do quanto que nosso modelo tende a errar.
Para o modelo que criamos anteriormente, seu MAE é de  , ou seja, o modelo erra, em média, 14.5 pontos de eficácia, para mais ou para menos.
, ou seja, o modelo erra, em média, 14.5 pontos de eficácia, para mais ou para menos.
MSE
O MSE, ou Mean Squared Error, é muito similar ao MAE, mas ao invés de fazermos o módulo do erro, fazemos o seu quadrado. Isso também evita que erros negativos cancelem os positivos (pois o quadrado de um número negativo é positivo), mas tem uma vantagem a mais: penaliza erros maiores com mais “força”. Como elevar números ao quadrado aumenta números maiores proporcionalmente mais que números menores, esse erro tende a penalizar mais erros maiores.
Sua formula é a seguite:
 .
.
Para o nosso modelo, o MSE é de  .
.
Uma das desvantagens do MSE é que ele não é tão interpretável quanto o MAE. Se temos um erro  no MAE, sabemos que, em média, nosso modelo erra , para mais ou para menos. No entanto, como no MSE os erros são elevados ao quadrado, não dá para inferir algo prático sobre o seu valor.
no MAE, sabemos que, em média, nosso modelo erra , para mais ou para menos. No entanto, como no MSE os erros são elevados ao quadrado, não dá para inferir algo prático sobre o seu valor.
Uma coisa que podemos fazer para melhorar isso, no entanto, é tirar a raiz quadrada do MSE. Assim, conseguimos “normalizar” o valor do erro para um alcance que faz sentido lógico, mas continuamos penalizando valores maiores com mais intensidade. A raiz do MSE se chama RMSE (Root Mean Squared Error; Raiz da Média do Erro ao Quadrado). A RMSE para o nosso modelo é de  .
.
Coeficiente de Determinação
Além das funções de perda, como a MAE e a MSE, também temos outra métrica que é útil para entendermos a performance do nosso modelo de regressão polinomial: o Coeficiente de Determinação (ou ).
O coeficiente de determinação é um número que mede o quanto nosso modelo “explica” a correlação entre os features (x) e os targets (y). Um valor alto significa que nosso modelo explica essa correlação muito bem, isto é, modela de maneira acurada como uma variável afeta a outra.
Para calculá-lo, utilizamos:
 .
.
Onde  é o valor real,
é o valor real,  é o valor previsto e
é o valor previsto e  é a média dos valores reais. Ou seja, ele mede a relação entre o erro usando nosso moelo (MSE entre e ) e o erro usando apenas a média de todos os valores (MSE entre e ). Se nosso modelo não explica bem as relações, ele vai estar próximo de apenas usar a média de todos os valores como predição, resultando em um valor baixo. Já se ele estiver explicando bem as relações, o erro de usar a média de todos os valores vai ser muito mais alto que o erro de usar nosso modelo, resultando em um valorThe mais alto.
é a média dos valores reais. Ou seja, ele mede a relação entre o erro usando nosso moelo (MSE entre e ) e o erro usando apenas a média de todos os valores (MSE entre e ). Se nosso modelo não explica bem as relações, ele vai estar próximo de apenas usar a média de todos os valores como predição, resultando em um valor baixo. Já se ele estiver explicando bem as relações, o erro de usar a média de todos os valores vai ser muito mais alto que o erro de usar nosso modelo, resultando em um valorThe mais alto.
Regressão Polinomial Multivariada
Beleza, já fizemos um bom modelo bom para prever a eficácia das doses do remédio – mas fizemos isso ignorando a idade dos pacientes. Em geral, pacientes mais velhos podem precisar de doses maiores, especialmente entre adolescentes e adultos. Por isso, precisamos de alguma forma de adicionar essa variável “Idade” ao nosso modelo.
Vamos chamar a dose de  e a idade de
e a idade de  . Agora, podemos fazerum modelo polinomial para cada parâmetro. Vamos chamar nosso modelo de
. Agora, podemos fazerum modelo polinomial para cada parâmetro. Vamos chamar nosso modelo de  :
:

e .
.
E, para termos nosso modelo copmleto, apenas somamos os dois, e adicionamos termos de interação entre a idade e a dose, sendo eles:  , que representa a interação entre os dois:
, que representa a interação entre os dois:
 .
.
Detalhe importante: esses termos de interação não são sempre utilizados. As vezes, usa-se apenas o simples (nesse caso,  ), e algumas vezes não se usa nenhum deles. Mas, por completude, mencionei todos.
), e algumas vezes não se usa nenhum deles. Mas, por completude, mencionei todos.
Isso funciona para nosso modelo com idade e dose , mas podemos generalizar esse modelo para quaisquer features. Assim, poderíamos chamar nossos features de  , e generalizar todas as interações usando somatórias que fazem todos os pesos cruzados. No entanto, para a simplicidade desse guia, e considerando que essas interações completas raramente são utilizadas, vamos pular essa etapa.
, e generalizar todas as interações usando somatórias que fazem todos os pesos cruzados. No entanto, para a simplicidade desse guia, e considerando que essas interações completas raramente são utilizadas, vamos pular essa etapa.
Vamos ver como fica nosso modeo de regressão polinomial de melhor ajuste para nossos dados:

Onde  .
.
Um detalhe importante de perceber aqui é que, como temos dois features, ficamos com um gráfico tri-dimensional, onde nosso modelo é representado por uma superfície tri-dimensional. Conforme vamos criando modelos com mais e mais features, para problemas mais complexos, a dimensionalidade vai aumentando: com 3 features, nosso modelo é representado por um hiperplano (tipo um plano como o da imagem acima, mas em 4 dimensões), e assim por diante. Modelos avançados de IA – incluindo o ChatGPT e modelos de geração de imagens -, com milhares de features e pesos, modelam planos hiper-dimensionais que definem suas saídas, assim como esse modelo de regressão que criamos.
Intuição Matemática
Essa sessão vai entrar em detalhes em como os pesos dos modelos que fizemos são definidos. Você não precisa entender isso em detalhes, mas é interessante se quiser realmente entender como esses algoritmos funcionam por baixo dos panos.
Até agora, eu apenas apresentei os modelos ajustados aos dados, como se tivesse feito uma mágica que me contou os pesos certinhos de melhor ajuste. E na prática, foi mais ou menos isso que aconteceu! Eu só usei uma biblioteca no python que calcula os pesos de melhor ajuste, e utilizei eles.
Mas, para realmente entender o que aconteceu, vamos dissecar esse processo, chamado de otimização.
O método que utilizaremos aqui é o OLS, ou Ordinary Least Squares. Como o nome diz, ele vai achar os pesos que garantem o menor erro ao quardado (seguindo a loss MSE, que vimos antes). O NOIC já tem um artigo explicando ele, que você pode checar e depois voltar aqui: Losses e otimização.
Agora que você já sabe como o OLS funciona, vamos aplicar ao nosso caso. Assim como no OLS de regressão linear, teremos um vetor  com todos os pesos. Ele pode ou não ter os termos de interação – depende do nosso problema. De qualquer forma, a solução fica a mesma:
com todos os pesos. Ele pode ou não ter os termos de interação – depende do nosso problema. De qualquer forma, a solução fica a mesma:

onde  é o nosso vetor de dados + 1 e Y é o nosso vetor de dados.
é o nosso vetor de dados + 1 e Y é o nosso vetor de dados.
Relembrando esse gráfico:
O tem vários vetores com a idade, dosagem e  (para o viés), e o
(para o viés), e o  é um vetor com os scores de eficácia.
é um vetor com os scores de eficácia.
Usando a fórmula, conseguimos os parâmetros que minimizam a loss. Se quisermos minimizar outra loss, é só refazer a dedução que fizemos no artigo Losses e Otimização, zerando as derivadas parciais do residual, mas usando essa outra loss.